Python与C家族的语言相似,但是有一些明显的区别和独特的属性。
Python与C和ST等语言之间最明显的语法区别是Python解析器通过缩进识别块结构。没有BEGIN/END或大括号{}来标识IF/ELSE条件,FOR和WHILE循环或函数的块。
注释以#开头,并扩展到该行的末尾。在源代码的第一行和第二行中,你可以设置一个特殊的标记来声明文件的编码。如果不需要ASCII字符,我们建议你使用UTF-8作为编码。
出于调试目的,可以使用print简单输出。使用%运算符,可以实现类似于C函数printf()的功能。输出显示在CODESYS的消息视图中。
.例如:print
# 编码:utf-8
# 用参数i定义一个函数
def do_something(i):
# 如果分支
if i>0:
print("The value is: %i" % i)
sum += i
print("The new sum is: %i" % sum)
# else if (可选,可以没有一个或多个elif分支)
elif i=0:
print("The sum did not change: %i" % sum)
# 和最后的else分支(也是可选的)。
else:
handle_error()
# 无尽的while循环
while True:
print("I got stuck forever!")
属于同一块的所有内容都必须缩进相同的距离。缩进的大小无关紧要。括号和花括号等元素的优先级高于缩进。因此,以下代码段是完全正确的,即使它是以不良的编程风格编写的:
.例如:缩进
# 警告:下面的样式不好。不要轻易尝试!
if foo >= bar:
print("foobar")
else:
print(
"barfoo"
)
为避免歧义,请勿在文件中混用制表符和空格。
 |
这时,在Python 3中混合使用制表符和空格会导致语法错误。 官方的Python样式指南建议缩进四个空格,并包括一些好坏样式的示例。Python教程总结了编码风格。 |
Python区分大小写,与ST相似且相反。关键字,比如def,if,else,和while,必须为小写(与ST规则相反:关键字为大写)。两个标识符(例如“ i”和“ I”)也标识两个不同的变量。
以下关键字在Python中保留,并且不允许用作变量,函数等的标识符:and | as | assert | break | class | continue | def | del | elif | else | except | exec | finally | for | from | global | if | import | in | is | lambda | not | or | pass | print | raise | return | try | while | with | yield.
Python 3定义了另外四个关键字:False | None | True | nonlocal.虽然前三个确实很新,但前三个已经是Python 2中的预定义常量,不应将其用于任何其他目的。

变量和数据类型
Python是一种功能强大的动态类型化语言-所有类型信息都在运行时进行评估。变量保存对对象的引用,并且对象知道其类型,而不是变量。当程序员尝试执行不可能的操作(例如,添加整数和字符串)时,Python在运行时引发异常。
因此,没有变量及其类型的声明。在Python中,仅创建变量以为其分配值。这在类型强且静态的C和ST中完全不同。每个变量都用一种类型声明,并且在编译时,编译器检查该类型和运算符是否被允许。
请参阅以下示例来处理变量:
.例如:变量
# 将整数1分配给变量i(也“创建”变量”)
i = 1
# 将字符串“ foobar”分配给变量s
s = "foobar"
# 将5加到整数i-等于i = i + 5
i += 5
# 结果为有整数6。
# 尝试添加i和s-这将在执行时引发异常
# TypeError:+不支持的操作数类型:'int' and 'str'
result = i + s
# 也可以通过删除变量来“取消声明”变量。
# 进一步访问变量i会引发NameError异常,
# 因为该变量已不存在。
del i
i += 5 # 现在抛出一个异常:NameError:名称“ i”未定义
所有现有变量仅引用一个值。Python中没有任何未分配或未初始化的变量。为了表达缺少值,Python提供了一个特殊的对象:None。在C或ST中,你可以使用空指针。尽管None实际上是NoneType类的现有实例,但其唯一目的是表示“此处没有值”。
数值类型和浮点数
与IEC或C中的数十种整数类型相比,Python中只有一种整数类型。Python中的整数类型没有固定大小。相反,它们会根据需要增长,并且仅受可用内存的限制。
.例如:Integers.py
from __future__ import print_function
i = 1
print(i)
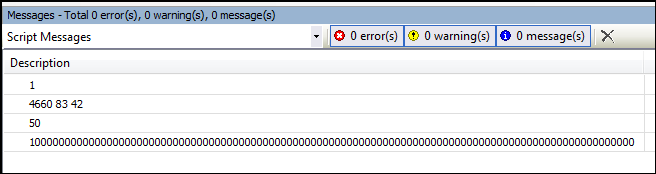
j = 0x1234 # 十六进制数,IEC中为16#1234,十进制为4660
k = 0o123 # 八进制数,IEC中为8#123,十进制为83
l = 0b101010 # 二进制数,IEC中为2#101010,十进制为42
print(j, k, l)
m = (2 + 3)*10 # k is 50 now
print(m)
n = 10 ** 100 # 10 to the power of 100
print(n)
输出结果:
Python中只有一种浮点类型,与IEC数据类型LREAL相似。它提供64位IEEE浮点运算。
语法在大多数情况下类似于基于C的语言:
.例如:浮点数类型
# 一个简单的浮动数...
a = 123.456
# 包含整数值2的浮点数
b = 2.
# 前面的零可以省略
c = .3 # same as 0.3
# 指数/科学表示
d = -123e-5
两种特殊情况是True和False,这两个常量定义布尔真值。它们的行为类似于整数值0和1,但将它们转换为字符串并返回其名称时除外。
.例如:Booleans.py
# 布尔值的行为类似于整数,但转换为字符串时除外。
# 内置函数“ type”可用于查询值的类型。
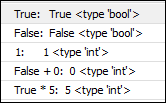
print("True: ", True, type(True))
print("False: ", False, type(False))
print("1: ", 1, type(1))
print("False + 0: ", False + 0, type(False + 0))
print("True * 5: ", True * 5, type(True * 5))
输出结果:
在IronPython中,字符串始终采用Unicode,且为任意长度。如果将它们括在’或”中,则没有任何区别。字符串也可以使用三引号 ""”或''’,以允许使用多行字符串文字。
与C相似,特殊字符可以通过反斜杠(\)排除:作为比较,IEC中为此使用了美元符号($)。
还有一些原始字符串,它们对反斜杠具有其他规则。当字符串应具有文字反斜杠时,这是实用的。例如:Windows文件路径或正则表达式。
.例如:Strings.py
# 编码:utf-8
from __future__ import print_function
a = "a simple string"
b = 'another string'
c = "strings may contain 'quotes' of the other type."
d = "multiple string literals" ' are concatenated ' '''by the parser'''
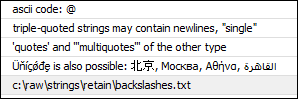
e = "Escaping: quotes: \" \' backslash: \\ newline: \r\n ascii code: \x40"
f = """triple-quoted strings may contain newlines, "single"
'quotes' and '''multiquotes''' of the other type"""
g = "Üňíçǿđȩ is also possible: 北京, Москва, Αθήνα, القاهرة"
h = r"c:\raw\strings\retain\backslashes.txt"
# 我们遍历上面定义的所有变量的序列:
for i in (a,b,c,d,e,f,g,h):
print(i) # 打印变量的内容
输出结果:
Python没有字符类型。通过使用长度为1的字符串来表示字符。这样,通过字符串进行迭代或在字符串中进行索引将返回一个单字符字符串。
另请参考
列表和元组(数据集)
列表和元组基本上对应于C和IEC中的数组,但是有一些明显的区别:
列表是使用list()构造函数创建的。或者,你可以使用方括号[]。使用tuple()构造函数或括号()创建元组。
.例如:list_tuples.py
from __future__ import print_function
print("Testing tuples and lists")
# 我们定义一个从1到10的元组:
t = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
print("Tuple:", t)
# 我们可以访问元组的第6个元素。
# 与C中一样,索引计数从0开始。
print("Element 5:", t[5])
# 使用范围语法,订阅功能更强大:
print("Range[2:5]:", t[2:5]) # 下限是包容性的,上限是排斥性的。
print("Range[2::2]:", t[2::2]) # 从第三个元素开始,并打印每个第二个元素。
print("Range[-3:-1]:", t[-3:-1]) # 从最后一个元素的第3个开始,在最后一个元素的前面结束(上限是唯一的)
print("Range[::-1]:", t[::-1]) # 负步距-向后打印
# 列表类似于元组...
l = [11, 12, 13, "8", t] # 包含混合类型:3个整数,一个字符串和上面定义的元组。
print("List:", l)
# ... 但是可以动态添加或删除元素。
l.append(9) # Add a 9 to the list.
print("List with 9:", l)
print("List Range[3:6:2]:", l[3:6:2]) # 打印第4个和第6个元素。
del l[1] # 删除索引1、12处的元素。
print("Removed[1]:", l)
del l[1:3] # 删除索引1和2、13和'8'处的元素。
print("Removed[1:3]:", l)
输出结果:
Python还具有哈希表类型(也称为“ hashmap”)。与列表相反,它可以用任何元素(例如字符串)进行索引。它的构造函数是dict(),其文字使用大括号{}声明。
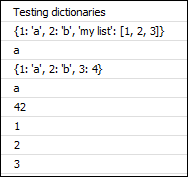
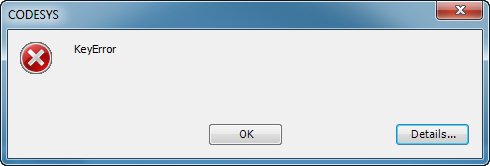
示例脚本dictionaries.py创建下面显示的输出。在最后一行中,脚本以“ KeyError”异常终止:
.例如:dictionaries.py
from __future__ import print_function
print("Testing dictionaries")
# 声明一个包含三项的字典,第三项是列表
d = {1: "a", 2: "b", "my list": [1, 2, 3]}
print(d)
# 打印元素1的值
print(d[1])
# 使用元素“my list”删除该值
del d["my list"]
# 给元素3赋值为4
d[3] = 4
print(d)
# 如果找不到密钥,则“ get”方法将返回第二个参数。
print(d.get(1, 42))
print(d.get(23, 42))
# 打印字典中的所有元素
for key in d:
print(key)
# 未知元素的索引访问将引发“ KeyError”异常!
print(d[23])
输出结果:
然后在最后一行中,脚本终止:
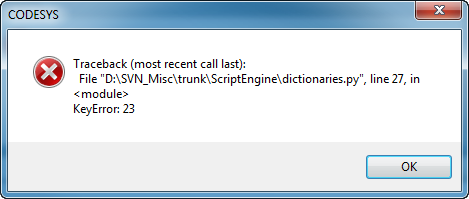
你可以通过单击详细信息按钮查看堆栈跟踪。在这里,你可以找到第27行和未知密钥23。